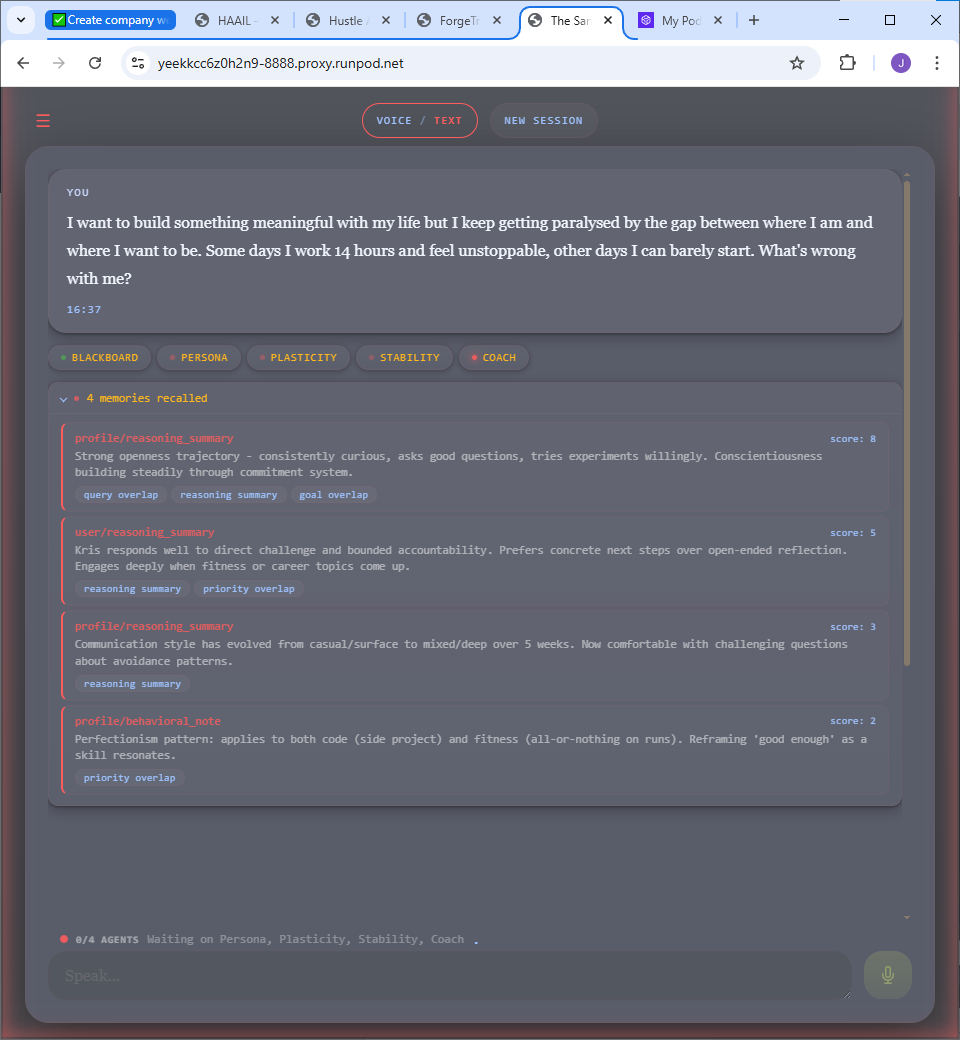
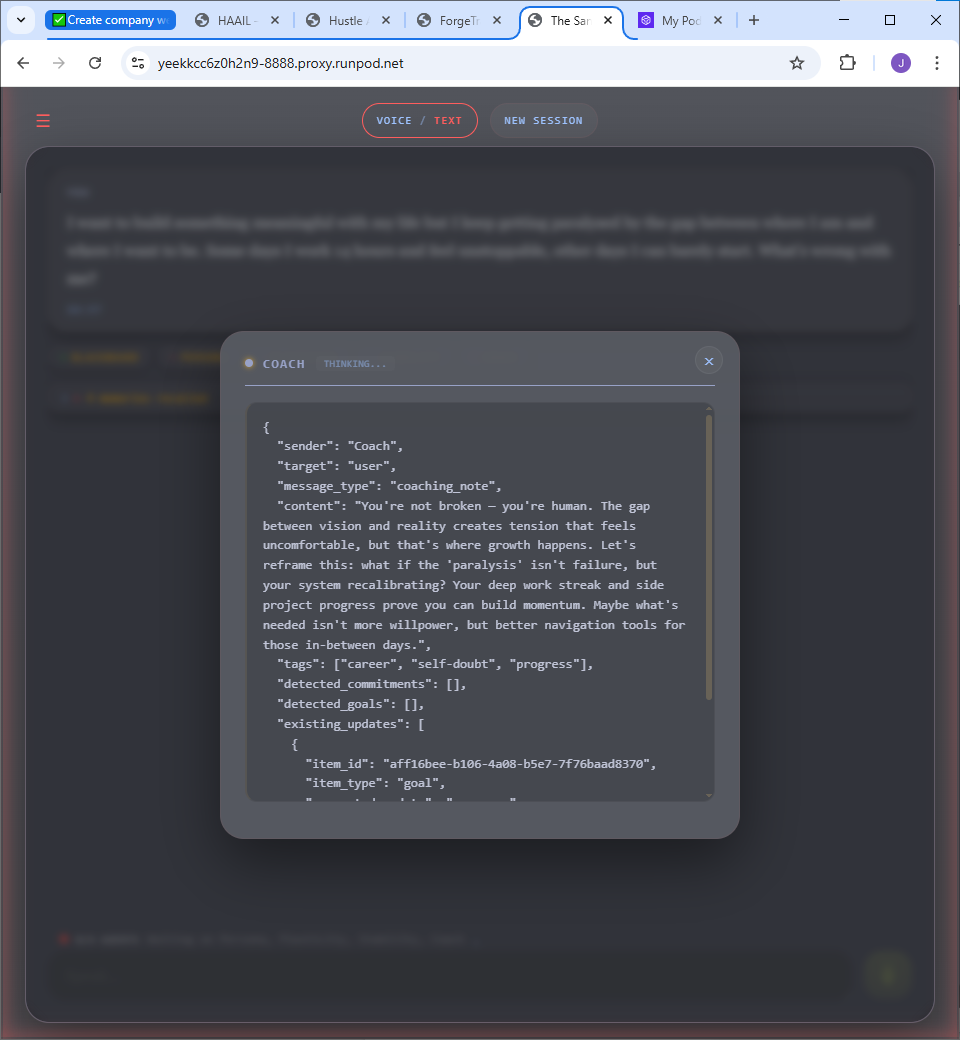
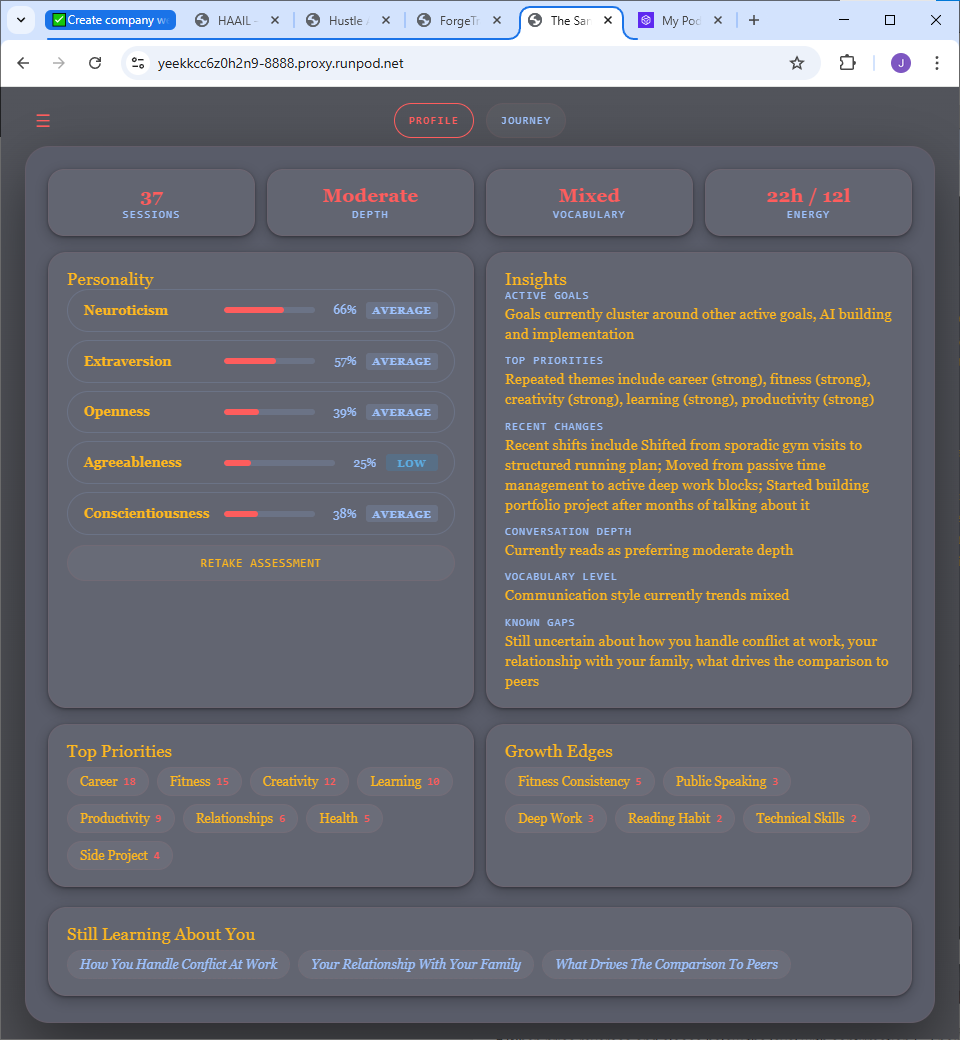
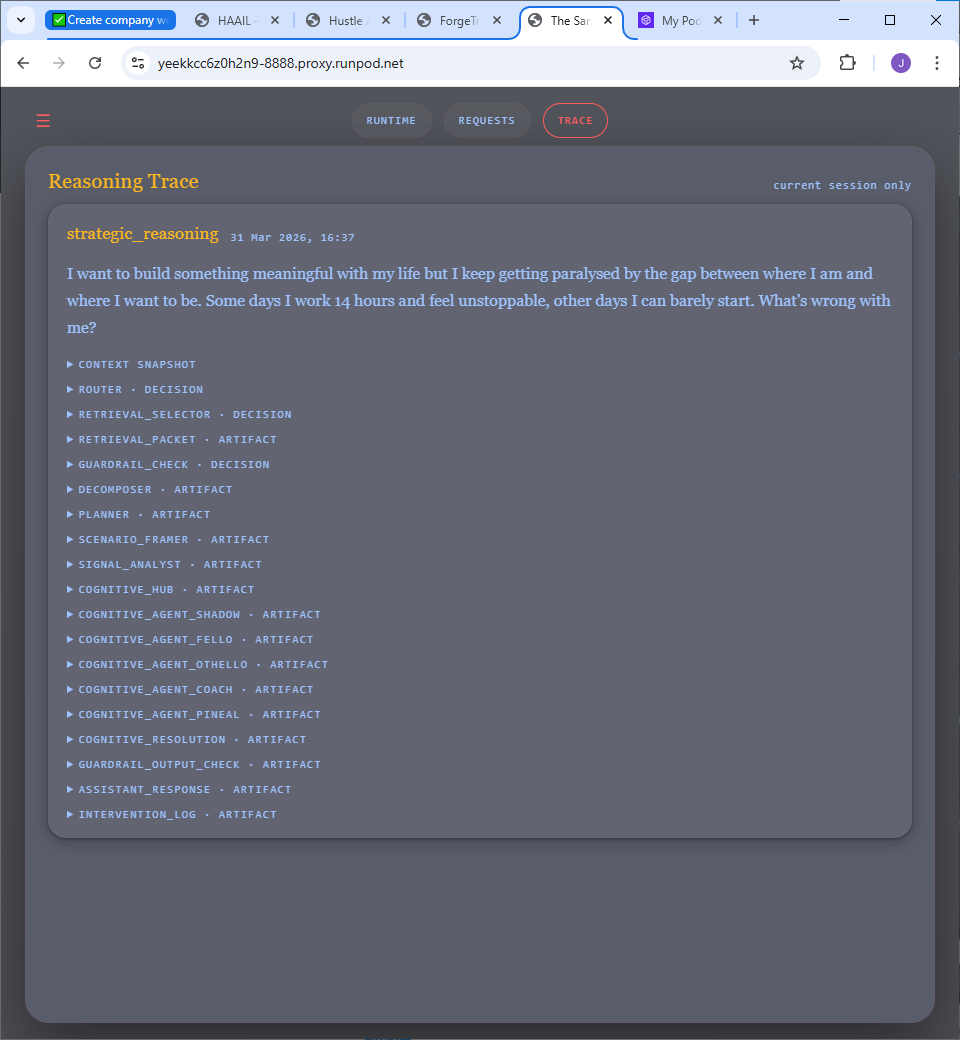
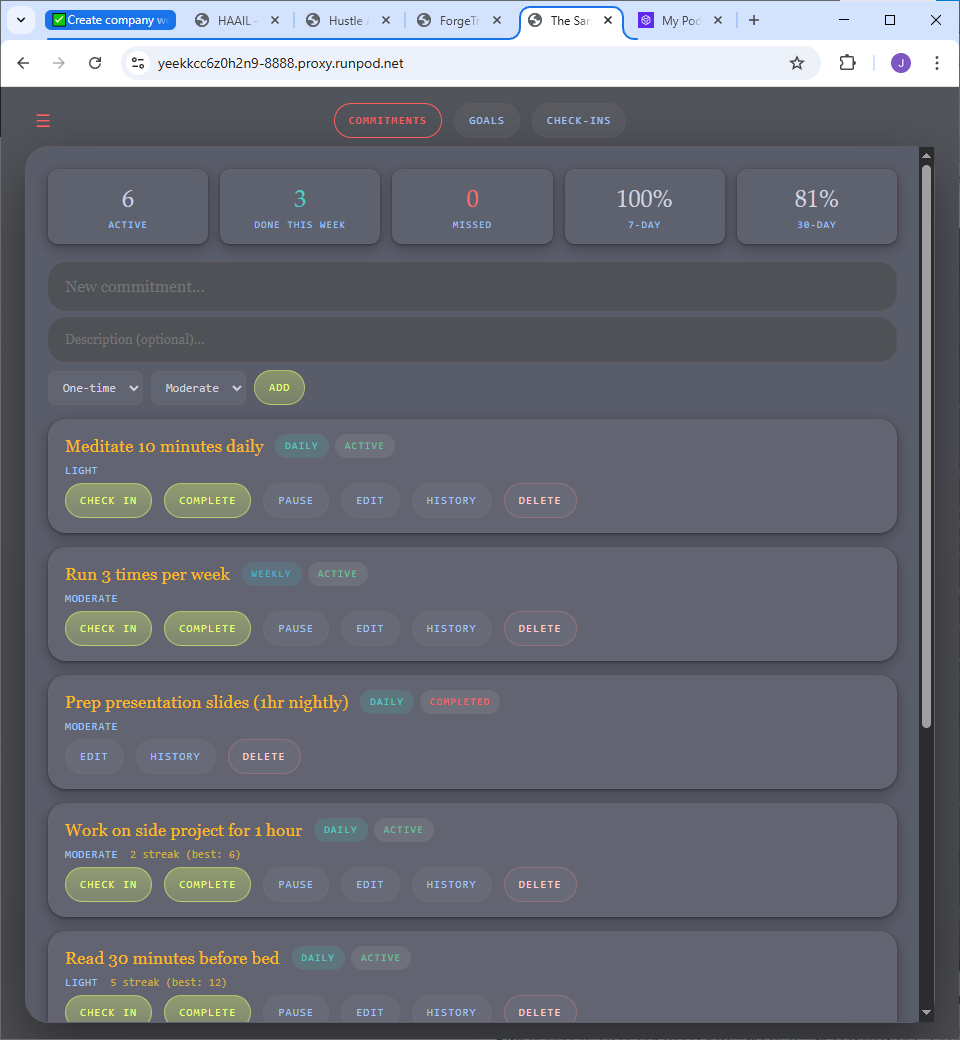
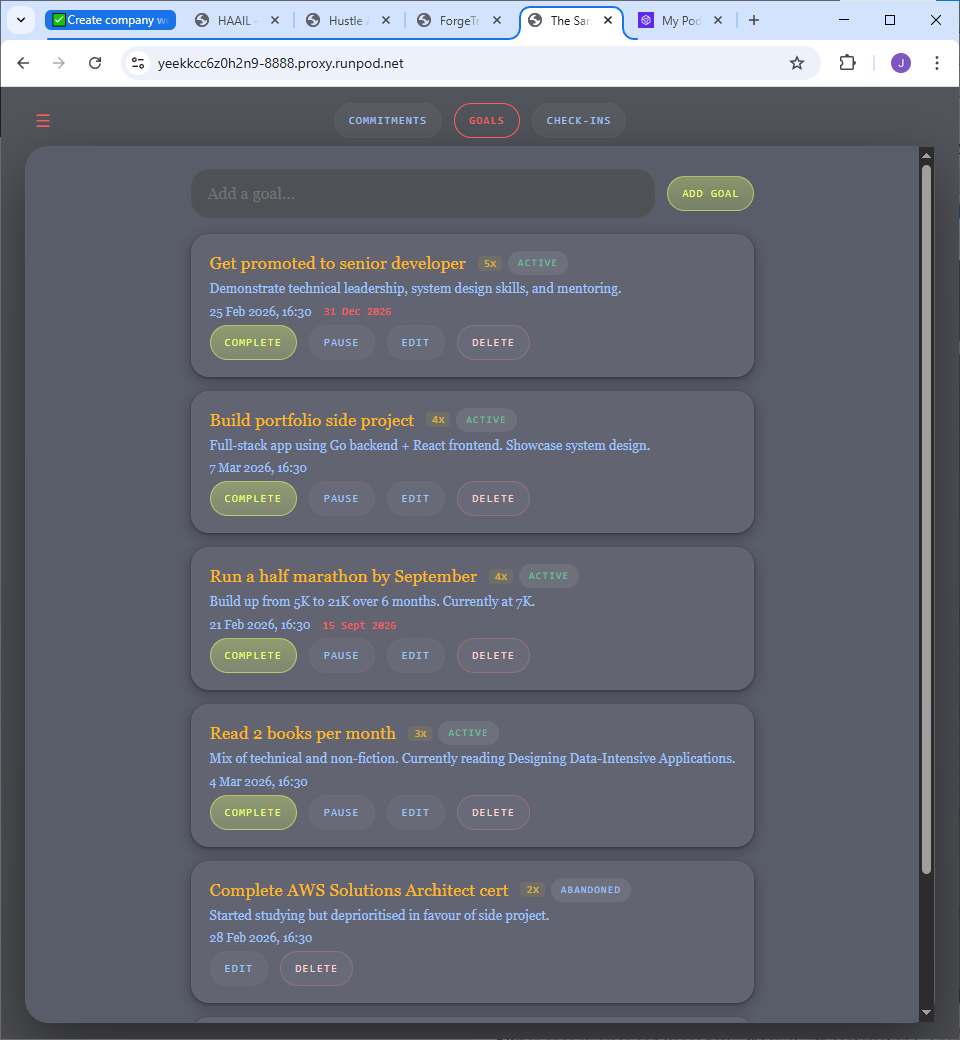
Inside the product
Built, working, and fully inspectable.
The user-facing response hides the machinery — but every agent decision is recorded and exposed. Pattern matches, risk assessments, personality scores, token costs, even the system prompts. This isn’t a mockup.